高德地图API展示Scrapy爬取的链家网房源
1.代码链接
https://github.com/happyte/buyhouse
2.最终效果图
3.实现思路
-
1.爬取的是链家网的成都地区的新房源,爬出房源的名字、价格、地址和url这四个。我是基于python的scrapy实现爬虫的。
-
2.在终端安装scrapy,使用命令pip install scrapy,安装完后新建项目scrapy startproject fangjia。
-
3.明确需要爬取的数据,在items.py文件中写入需要爬取的数据。在scrapy中,Item是用来抓取内容的容器,类似python中的字典
import scrapy
class FangjiaItem(scrapy.Item):
FANGJIA_ADDRESS = scrapy.Field() # 住房地址
FANGJIA_NAME = scrapy.Field() # 名字
FANGJIA_PRICE = scrapy.Field() # 房价
FANGJIA_URL = scrapy.Field() # 房源url
- 4.下面分析下网页,来到成都房源的首页,一共有19个分页,分页的url例如http://cd.fang.lianjia.com/loupan/nht1/,最后一个数字代表页数。查看网页源代码如下:

href="/loupan/p_chaygceqaausi/" 即为我们想要的相对路径,拼接http://cd.fang.lianjia.com 成http://cd.fang.lianjia.com/loupan/p_chaygceqaausi/ 即为我们需要的url。
-
5.使用xpath抓取上面的a标签中的href,
fang_links = response.xpath('//div[@class="list-wrap"]/ul[@id="house-lst"]/li/div[@class="pic-panel"]/a/@href').extract()抓取一个页面的所有的url集合,遍历上面的集合,请求具体页面。 -
6.来到一个具体页面分析,抓取我们要的数据标签位置
-
房源名字
-
房源单价
-
房源地址



抓取的代码如下:
name = response.xpath('//div[@class="name-box"]/a/@title').extract()[0]
url = response.xpath('//div[@class="name-box"]/a/@href').extract()[0]
price = response.xpath('//p[@class="jiage"]/span[@class="junjia"]/text()').extract()[0]
address = response.xpath('//p[@class="where"]/span/@title').extract()[0]
- 7.把上面抓取的数据放入item中,创建一个items.py定义的FangjiaItem类对象,最终输出这个对象item
item['FANGJIA_NAME'] = name
item['FANGJIA_ADDRESS'] = address
item['FANGJIA_PRICE'] = price
item['FANGJIA_URL'] = 'http://cd.fang.lianjia.com'+url
yield item
- 8.在scrapy工程的settings.py文件中要设置如下代码:
ITEM_PIPELINES = {
'fangjia.pipelines.FangjiaPipeline':300
}
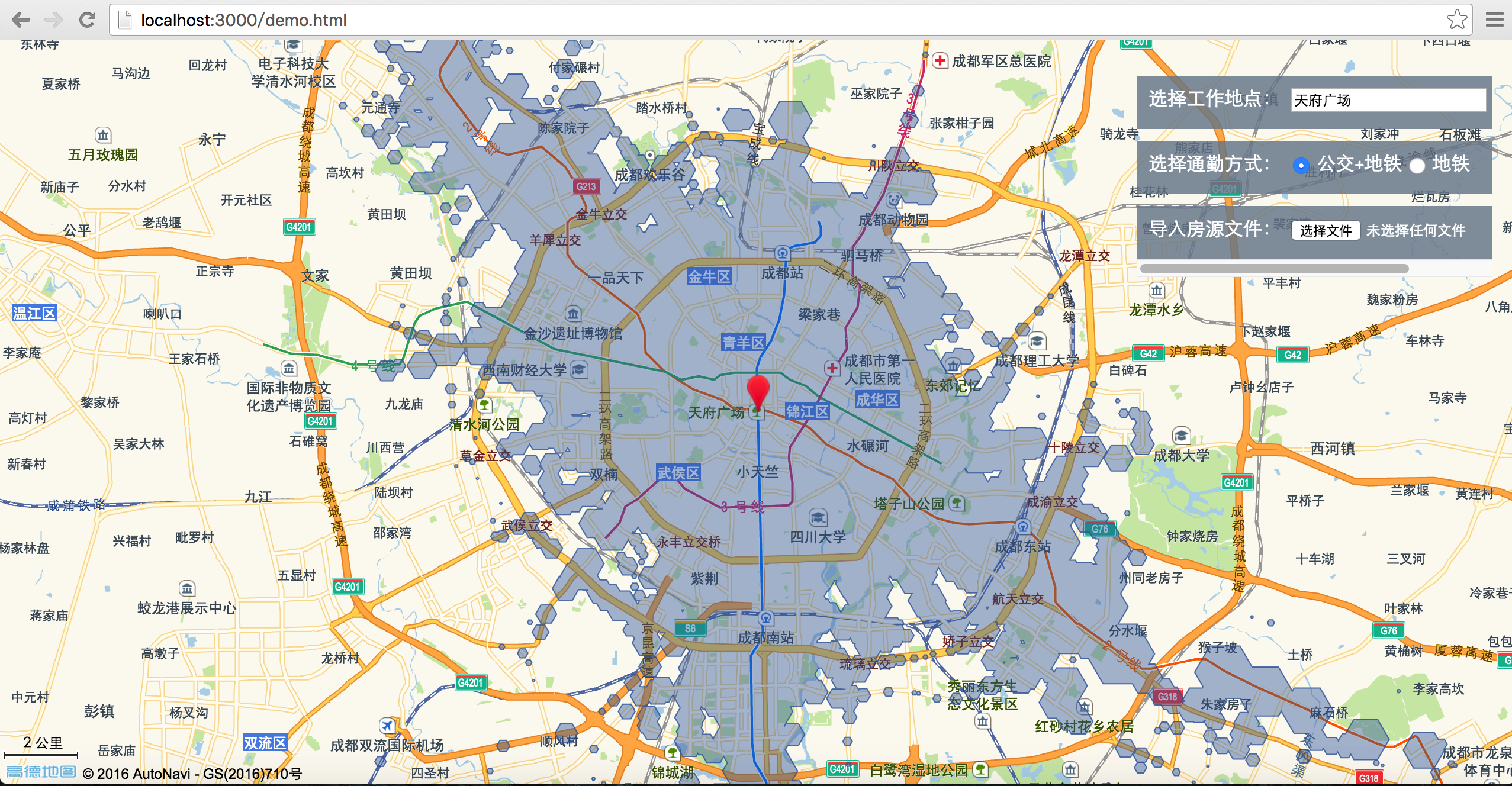
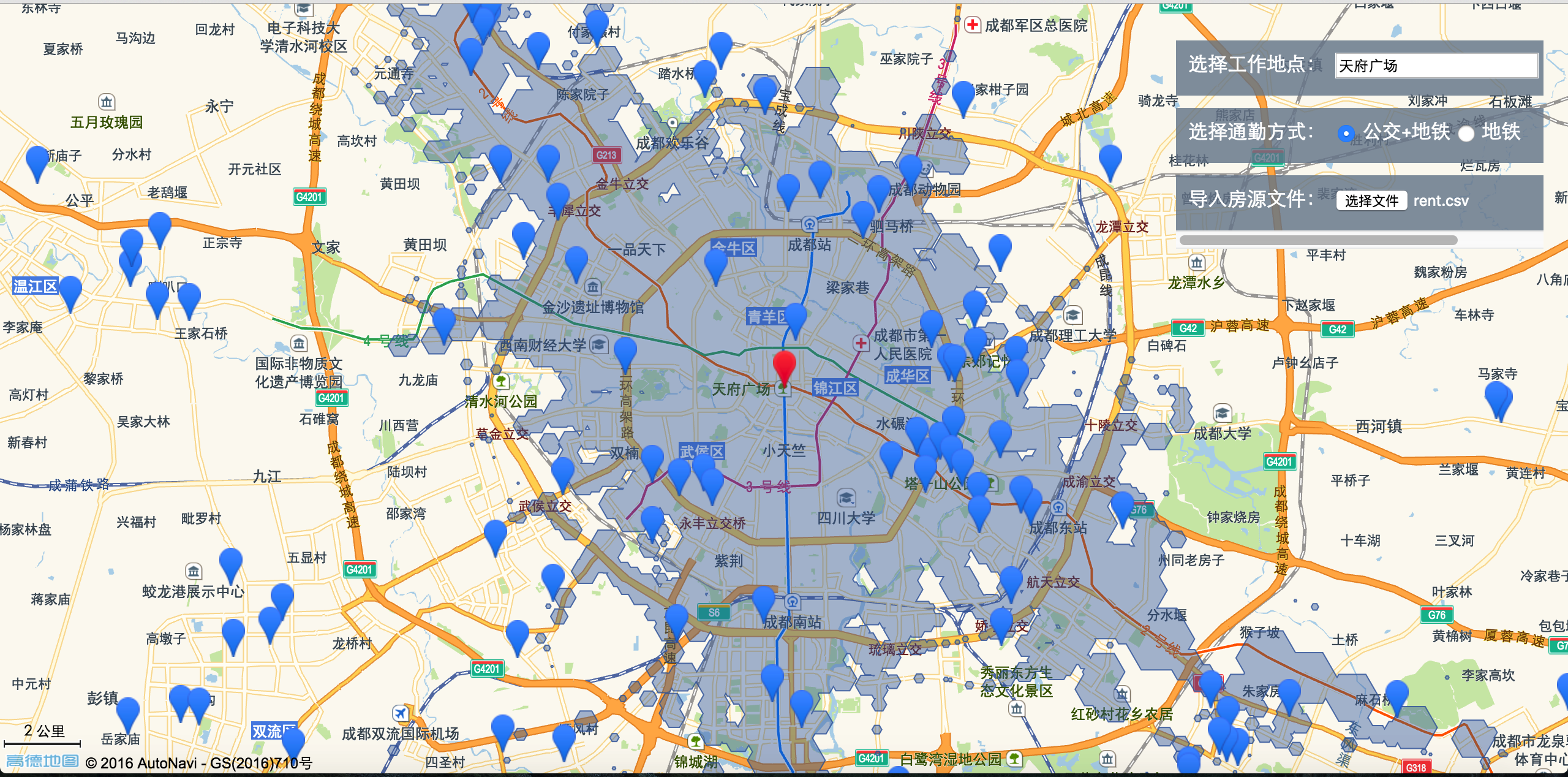
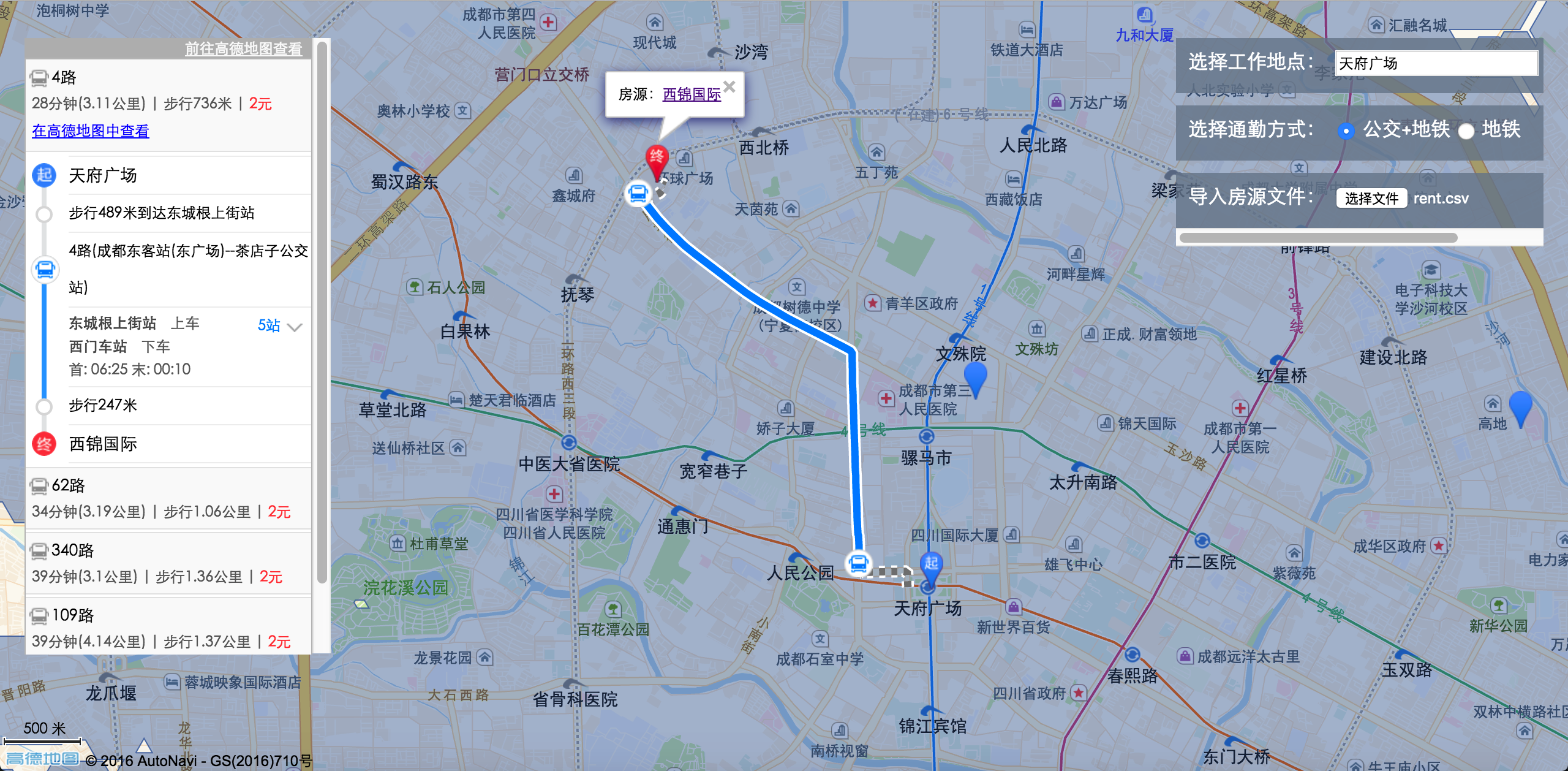
高德地图API调用
采用高德地图对房源进行可视化操作,在工程根目录下创建demo.html文件,页面大框架可直接从示例中心复制:高德 JavaScript API 示例中心http://lbs.amap.com/api/javascript-api/example/map/map-show/。具体可以看我仓库中的demo.html文件。